Distributed hash table
A distributed hash table (DHT) is a class of a decentralized distributed system that provides a lookup service similar to a hash table. (key,value) pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key.
对于一个key/value对,DHT在分布式集群中,提供像HashTable一样的服务,例如简单快捷的存取、查询。

DHTs form an infrastructure that can be used to build more complex services, such as anycast, cooperative Web caching, distributed file systems, domain name services, instant messaging, multicast, and also peer-to-peer file sharing and content distribution systems.
Properties
Unlike unstructured P2P, DHT is tightly coupled between nodes and file locations. (when request a content, directly go to the content instead of searching by flooding)
DHT has the following properties:
Autonomy and Decentralization: the nodes collectively form the system without any central coordination.
Fault tolerance: the system should be reliable (in some sense) even with nodes continuously joining, leaving, and failing.
Scalability: the system should function efficiently even with thousands or millions of nodes.
Building a DHT
- Hash function that maps a file to a unique ID. Eg. hash(“Harry Potter”) -> 3912.
- Distribute range space for all nodes in the network.
- The desinated node stores the location of the file. (this is indirect approach)

Search in DHT
- Search query routed to the node whose range covers the file.
- Each node would retains a routing information that is implemented in a fully distributed manner (i.e. no central point, no single point of failure).
There is different hashing and routing techniques associated with DHT. The most important is Consistent Hashing and Chord Routing.
Consistent Hashing
Consistent hashing is a special kind of hashing such that when a hash table is resized and consistent hashing is used, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots.
Motivation
In most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped. Specifically, the 3 cases below can end up in a technology crisis:
leaves/failures - 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1);
join - 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1)
scalability - 由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
Technique
Consistent hashing is based on mapping each object to a point on the edge of a circle. The system maps each available machine to pseudo-randomly distributed points on the edge of the same circle.
- 假定哈希key均匀的分布在一个环上
- 所有的节点也都分布在同一环上
- 每个节点只负责一部分Key,当节点加入、退出时只影响加入退出的节点和其邻居节点或者其他节点只有少量的Key受影响
For a very detailed steps of consistent hashing, read this Chinese blog.

In this way, 一致性Hash在node加入/离开时,不会导致映射关系的重大变化。
Routing (searching)
Simple Routing would search successor node, and runtime is linear. These node would keep O(1) routing information, and spend O(n) time in query routing.
Otherwise, we make every node store ID and IP of all nodes, thus query routing takes O(1) but routing information is O(n).
We’ll now discuss Chord Routing.
Chord Routing
Each node stores more info closely following it on the identifier circle than nodes further away. That is, the subsequent nodes at position 1, 2, 4, 8, 16, 32… (each entry is called a finger)

为网络中每个Node分配一个唯一id(可以通过机器的mac地址做Hash),假设整个网络有N 个节点,我们可以认为这些整数首尾相连形成一个环,称之为Chord环。两个节点间的距离定义为节点间下标差,每个节点会存储一张路由表(Finger表),表内顺时针按照离本节点2、4、8、16、32.……2i的距离选定log2N个其他节点的ip信息来记录。
Routing information maintained at each node: O(logN).
Query routing take O(logN) time.
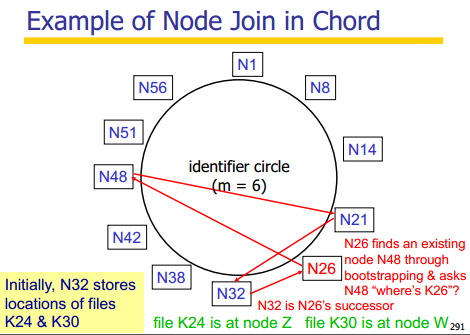
Join and leave in Chord
It’s very much like insertion and removal in Doubly Linked List. Read it yourself.
Special thanks to the online resources written by some CSDN bloggers.