From Level 0 to Level 1
Refer to the previous question. How can we improve???
- performance
- scalability
- robustness
performance
A better algo: Inverted Index

Avg performance increase to ~ 20ns (with some optimization of MapReduce procedure, discuss later).
Max QPS increase to 50.
scalability
Use a dispatcher to re-direct the requests to multiple machines.

How many machines do we need then?
Well we need 500 QPS. The algo above achieves ~ 50 QPS. Should we need 10 machines?
The answer is NO. A machine with 8 (or 16) core CPU could be able to handle.
We can also have a hot-standby, to be safe.
hot standby is used as a failover mechanism to provide reliability in system configurations.
When a key component fails, the hot spare is switched into operation.
robustness
Tips about system design for senior engineers:
Draw 1 machine first. This machine can contains multiple datasets and run multiple processes.
On top of this machine, the interface layer is one single Manager process. The Manager is in charge of almost everything: handling data lost, handle high concurrency, copy multiple instance of itself…
Like this:
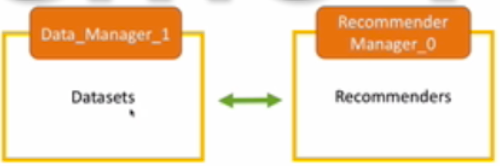
Back-end
Now we need a cluster of datasets (which has Manager on top of it), and a cluster of Recommenders. Manager is in charge of copying multiple instances.
Dataset can be put in different physical locations. Recommender don’t really need, cuz it’s only do calculation job.
Receiving requests
Just now we used Receptionist (or Dispatcher) to handle request. Now we use a Web service (eg. Apache). It’s not necessary to make it a cluster.
Big Brother
We need a monitor system to oversee everything.
Also, Big Brother is in charge of heart-beat. If not received, Big Brother have some double-check machanism.
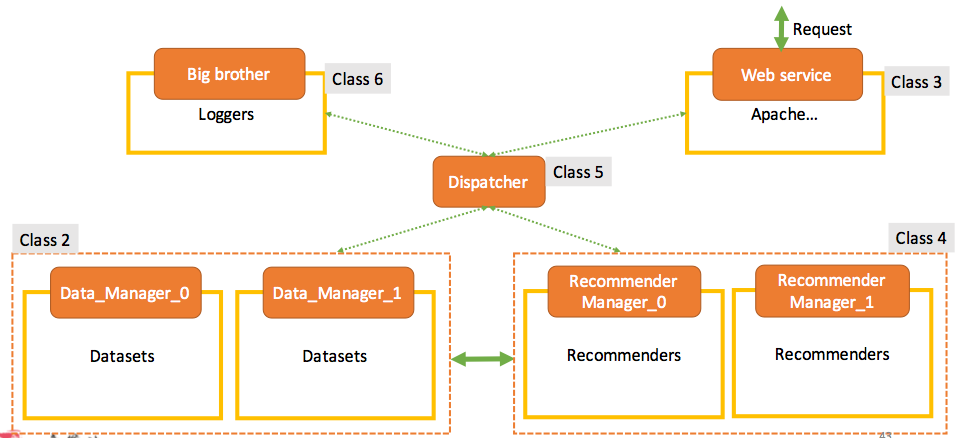
Connecting the dots
Dispatcher is used to connect the 4 components. It’s like a messaging queue that collects and distributes jobs among everybody (eg. control and distributed info).
It can be stateful or stateless.
Keep in mind the connection between Dataset and Recommender remains. It’s slow going thru Dispatcher.
Distribute it
During development, the 5 components can be put on same machine. When we deploy distributely, we use Socket connection (keep alive) to connect them.
Notice the Web Service is connection heavy, which consume large CPU and RAM resource. It’s better to seperate to one machine.
Big brother is read/write heavy, so it’s OKAY to put on same machine with Dispatcher.
Since Dataset and Recommender have data exchange, it’s a good idea to put on same machine.
Additional questions
Implement Dispatcher with consumer-producer model.