Overview
KISS - Keep It Simple, Sweetie.
In Today’s lecture:
- write a crawler
- thread-saft consumer & producer
- GFS, BigTable and MapReduce
- Top 10 keyword/anagram using MapReduce
- Log analysis
News Aggregator App
Info Collection
crawler
Info retrieval: rank, search and recommend.
They are in fact, all related to sorting.

Step 1, Info collection with crawler
crawler code
Python:
import urllib2
# request
url = "www.google.com"
request = urllib2.Request(url)
response = urllib2.urlopen(request)
page = response.read()
# save the file
webFile = open('webpage.html', 'web')
webFile.write(page)
webFile.close()
Network process
Use of socket.

Socket is like the cellphone in the Call Center example.
socket is an endpoint of an inter-process communication across a computer network.
Today, most communication between computers is based on the Internet Protocol; therefore most network sockets are Internet sockets.
What is socket? Where is it?
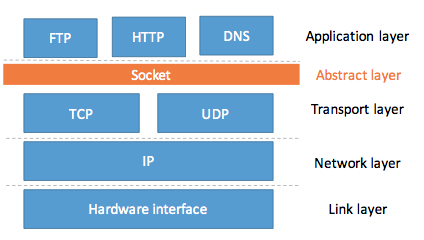
It’s in-between Application Layer (HTTP, FTP, DNS) and Transport layer (UDP, TCP).
Remembering that socket is like a cellphone. It is an abstraction layer, that hinds the complexity of lower layer, thus making it easier to sende data in application layer.
How is client connected to Server?
3-way handshake. Read [Design] TCP 3-Way Handshake
HTML
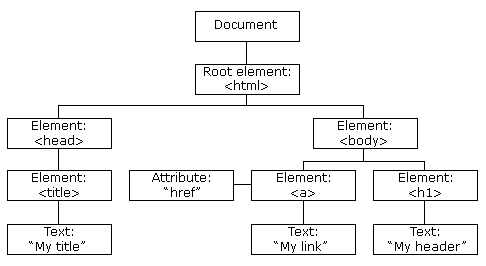
Document Object Model (DOM) is an application programming interface (API) for valid HTML and well-formed XML documents. It defines the logical structure of documents and the way a document is accessed and manipulated.
How to crawler all the news
- Go to index page
- identify all the links (regex)
Crawl more websites
Simple design
- use crawlers to find out all list pages
- send the new lists to a Scheduler
- Scheduler will use crawlers again, to crawl pages.

This design is bad, cuz there is crawler waste. How can we reuse these crawlers???
Adv design
Design crawler that can crawl both list and pages information.
Look at our crawler: the text extraction logic and Regex for abc.com and bfe.com are totally different. However, they both share the same crawling techniques.
So we pass in all info a crawler task needs. Like:
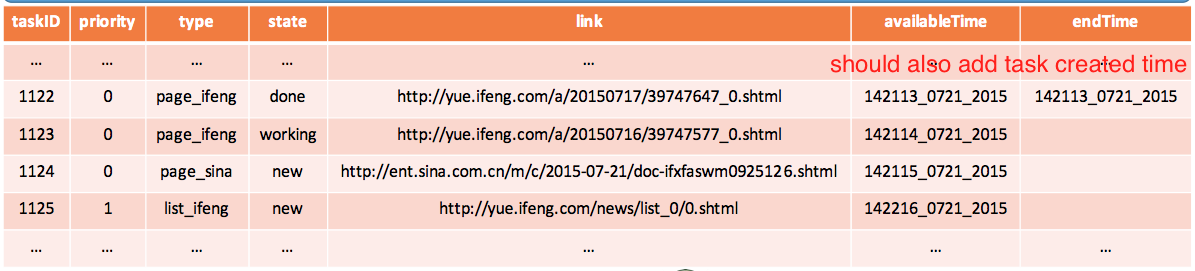
we gave more priority to list pages than content pages. Otherwise, your content get out of date soon.
Type include both list/content and source info.
status can be done, working, or new.
timestamps helps us make sure each crawler runs every hour (let’s say)
So when schedule pick the next crawler task to run, it will choose based on Priority. However if the timestamp (availableTime) is not yet reached, the job won’t be executed.
If you crawler runs until endTime and haven’t finish, force finish it. We should also add task created time to the info.
How to identify similar news?
Calculate the similarity between pages. More on this subject later.
How to design Scheduler?
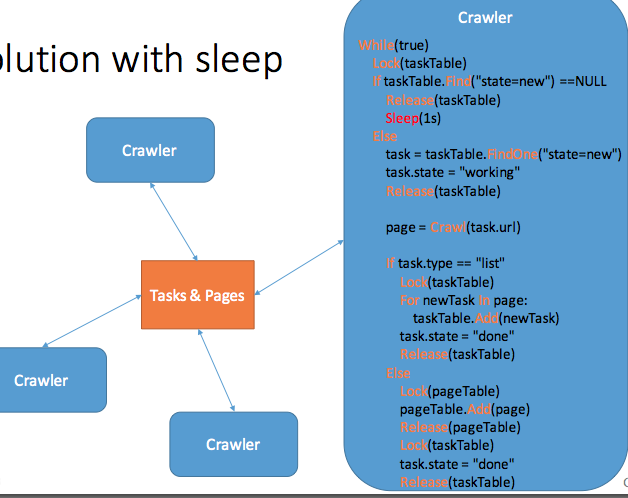
Solution with Sleep
Define variables:
taskTable<table> - store task lists
pageTable<page> - store page contents
task.url
task.state = new/working/done
task.type = list/page
code:
while (true) {
// get 1 task. If can't get, wait
taskTable.lock(); // IMPORTANT
newTask = taskTable.findOne(state == 'new')
if (!newTask) {
taskTable.unlock(); // IMPORTANT
sleep(1000); // IMPORTANT
continue;
}
newTask.state = "working";
taskTable.unlock();
// execute the task, and insert to
// either taskTable or pageTable
newPage = Crawl(newTask.url);
if (newTask.state === 'list') {
// insert all urls to taskTable
taskTable.lock();
foreach (url in newPage) {
taskTable.add(new task(url));
}
// mark the task as "done"
newTask.state = "done"; // IMPORTANT
taskTable.unlock();
} else {
// insert page content to pageTable
pageTable.lock();
pageTable.add(newPage.content());
pageTable.unlock();
// mark the task as "done"
taskTable.lock();
newTask.state = "done"; // IMPORTANT
taskTable.unlock();
}
}
Solution with Conditional Variable
What is Conditional Variable:
A condition variable is basically a container of threads that are waiting on a certain condition.
Monitors provide a mechanism for threads to temporarily give up exclusive access in order to wait for some condition to be met, before regaining exclusive access and resuming their task.

Look at last 3 lines of code. Before going to sleep, CV have to release the lock, so that other threads can access the taskTable.
Then CV goes to sleep. Right after CV has been waken up, it has to lock the mutex again.
Solution w/ cv:
while (true) {
// get 1 task. If can't get, wait
taskTable.lock();
newTask = taskTable.findOne(state == 'new')
if (!newTask) {
taskTable.unlock();
Cond_Wait(cond, taskTable); // Modified
continue;
}
newTask.state = "working";
taskTable.unlock();
// execute the task, and insert to
// either taskTable or pageTable
newPage = Crawl(newTask.url);
if (newTask.state === 'list') {
// insert all urls to taskTable
taskTable.lock();
foreach (url in newPage) {
taskTable.add(new task(url));
Cond_Signal(cond); // Modified
}
// mark the task as "done"
newTask.state = "done";
taskTable.unlock();
} else {
// insert page content to pageTable
pageTable.lock();
pageTable.add(newPage.content());
pageTable.unlock();
// mark the task as "done"
taskTable.lock();
newTask.state = "done";
taskTable.unlock();
}
}
Why Good: no need to busy-spin (example above have to always wait 1 second). So this solution is better.
Solution with Semaphore
This is better than Condition Variable, cuz it’s easier to implement. And Semaphore not only locks thread, it also can lock process.
CV locks on a certain condition. But Semaphore locks the numbers (of task, or resources etc).
Semaphore implementation (fairly difficult, read for interest):
Wait(semaphore) {
Lockf(semaphore);
semaphore.value--;
if (semaphore.value < 0) {
semaphore.processWaitList.Add(this.process);
Release(semaphore);
Block(this.process);
} else {
Release(semaphore);
}
}
Signal(semaphore) {
Lock(semaphore);
semaphore.value++;
if (semaphore.value <= 0) {
process = semaphore.processWaitList.pop();
Wakeup(process);
}
Release(semaphore);
}
Note that in Java and C++, Wait() == acquire() and Signal() == release(). Read more Jenkov’s post.
code w/ semaphore:
while (true) {
// get 1 task. If can't get, wait
Wait(numberOfNewTask); // Modified
taskTable.lock();
newTask = taskTable.findOne(state == 'new')
newTask.state = "working";
taskTable.unlock();
// execute the task, and insert to
// either taskTable or pageTable
newPage = Crawl(newTask.url);
if (newTask.state === 'list') {
// insert all urls to taskTable
taskTable.lock();
foreach (url in newPage) {
taskTable.add(new task(url));
Signal(numberOfNewTask); // Modified
}
// mark the task as "done"
newTask.state = "done";
taskTable.unlock();
} else {
// insert page content to pageTable
pageTable.lock();
pageTable.add(newPage.content());
pageTable.unlock();
// mark the task as "done"
taskTable.lock();
newTask.state = "done";
taskTable.unlock();
}
}
What happens in Line 3 ‘Wait(numberOfNewTask)’? Well, the programs checks on the numberOfNewTask (counter) variable, and:
- If there is 1 or more tasks, just proceed.
- If no tasks available, block itself and wait there. (Later someone will wake it up and it will resume).
Design an consumer-producer
Stay tuned for future post.