System design evaluation form
- work solution
- special cases
- analysis
- trade off
- knowledge base
Design guideline: 4S
Scenario
ask, features, qps, DAU, interfaces
Service
split, application, module
Storage
schema, data, sql, NoSql, file system
Scale
sharding, optimize, special case
Scenario
DAU?
Whta’s the DAU/MAU rate?
Chatting apps like wechat/whatapp has a rate of around 75%, but facebook/twitter is lower at 60%.
Enumerate the functions
- registration
- user profile display/edit
- upload image/video
- search
- post a tweet
- share a tweet
- timeline
- newsfeed
- follow/unfollow
QPS
concurrent user
150M user * 60 query/user / 606024s = average QPS = 100K
peak QPS = 3 * average QPS = 300K
fast growing product = 2 * peak QPS = 600K
read qps: 300K QPS
- write qps: 5K QPS
On average, a web server support around 1000 QPS, thus in this case, we need 300 servers to support the system.
Service
4 services for Twitter
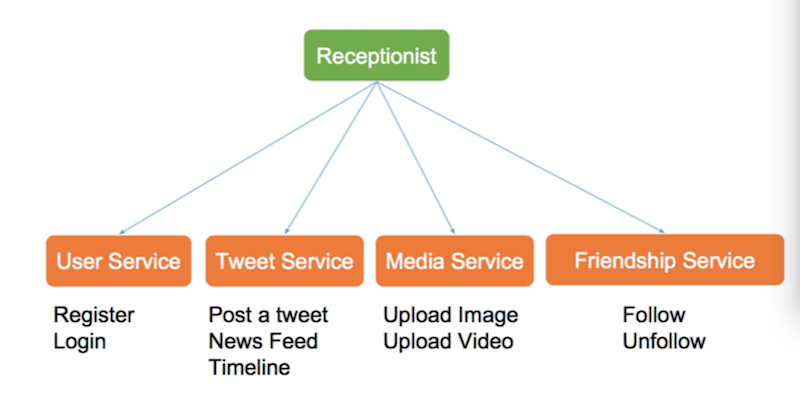
- user service
- register
- login
- tweet service
- post tweet
- news feed
- timeline
- media service
- upload image
- upload video
- friendship service
- follow
- upfollow
Storage
SQL
Good for accurate, small amount of data, more read than write. user table
NoSQL
Good for large amount of read/write, high scalability. tweets social graph (follower)
File System
Good for media files photo, video
Select the right DB
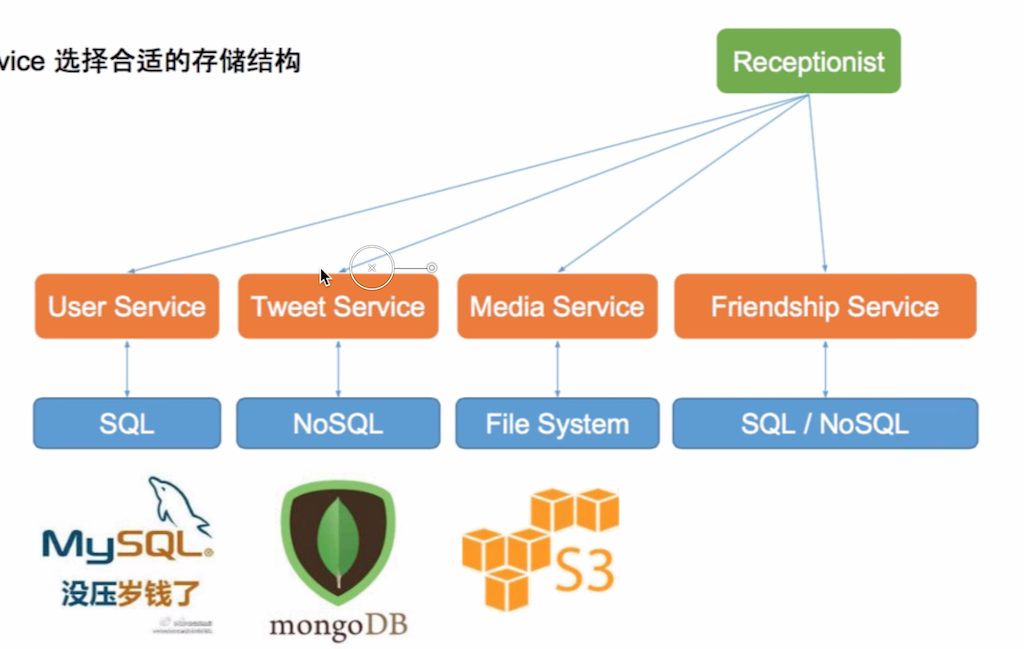
Question: can we use file system for tweets?
No, it’s hard to query. Eg. query all tweets of my friends.
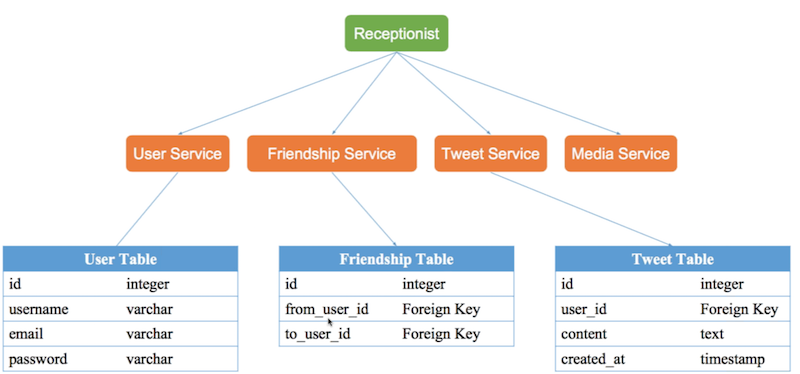
Design data schema
(optional) 3 tables needed:
- user table
- tweet table
- friendship table: this is not as straight forward, as it shall contain double directions info
Important: News Feed
pull model
Read top 50 feeds from top 100 friends, then merge sort by date. (note that user is getting sync-blocked here).
Post tweet is simple 1 DB write.
This design is bad, because file-system/DB read is slow. If you have N friends, you query O(N) DB queries. It’s too slow (and user is getting sync-blocked, too). We should have, ideally, <= 7 DB queries per web page.
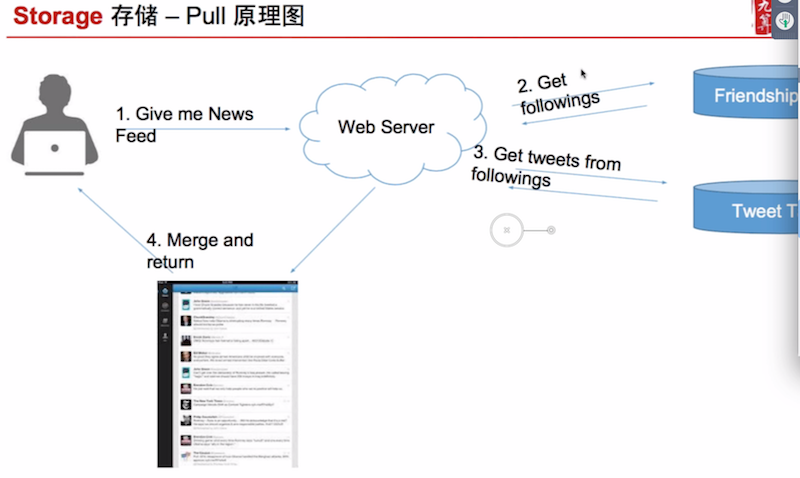
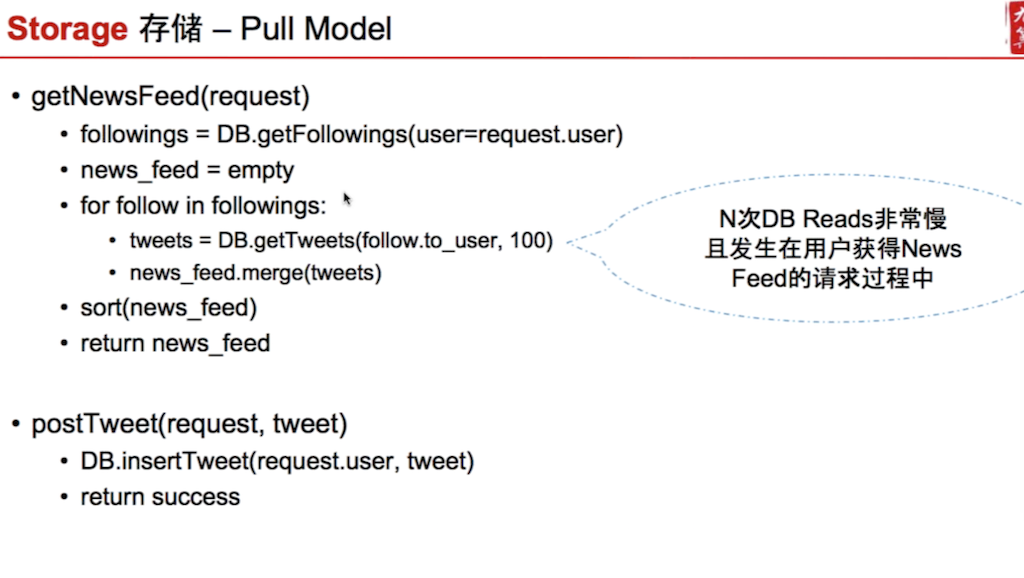
problem
- synchronously block user from getting news feed
- too many DB reads
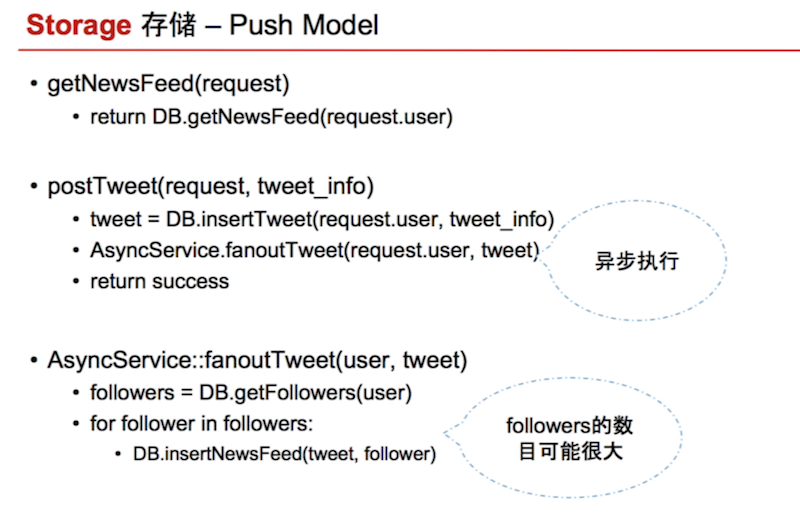
push model
Each person have a list storing new feeds. When friend post tweet, fanout to my feed list.
When I read, I simply read top 100 from the feed list. So read is 1 DB read.
Post tweet is N DB writes, which is slow. However this is done async, so it does not matter.
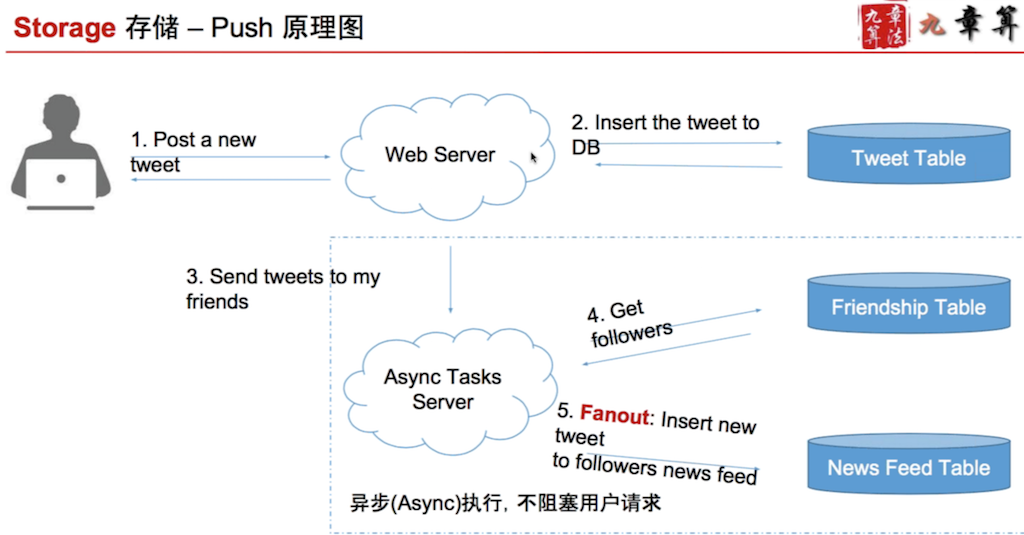
One example of async implementation: RabbitMQ
Scale
optimize pull model
Although it looks like push is faster than pull, facebook and twitter both use pull model.
- add cache for DB, reduce # of DB read
also cache each user’s news feed
your yesterday’s feeds are all cached, thus don’t need to read everytime.
optimize push model
- disk waste a lot, although disk is cheap
inactive user!
rank follower by weight, and don’t write to inactive user (eg. last login time)
if follower is toooo much, like Lady Gaga, user pull for Lady Gaga.
Tradeoff: Push + Pull model.
optimize ‘Like’ info
In tweet table, if we need to count(user) who liked, it’s gonna take forever.
We must denormalize this data!
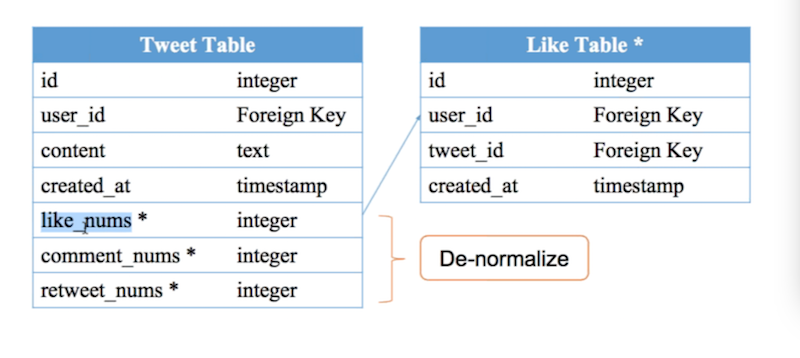
Denormalize: it’s duplicate info but we store in table, because of performance improvement.
Shortcoming: inconsistency!
- unless using SQL transaction, async failure can result in wrong counting number
- race condition
Solution: 1. use atomic operation 2. every day, schedule to update this number.
optimize thundering herd problem
When cache fails, all DB query will go to DB. This results in DB crash.
Hot spot (thundering herd)

Solution: hold all incoming queries (who fails cache), and only send 1 DB query. When result is returned, return to every query.