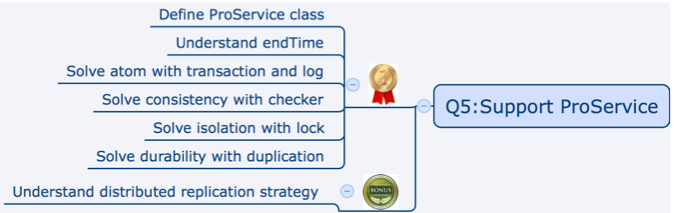
Question 5
Continue from last post, now let’s support VIP services.
User could buy VIP services using his acccount balance.
class ProService {
int userId;
double money;
long endTime;
public addMoney(){}
public buyPro(){}
}
Q5.1: System crash when purchasing VIP
Solution: transaction with log
WriteLOG
Transaction_1123: BEGIN
money=20; endTime=16_07_2016
If system crash happens here, system will read the log, recover and roll back all original data. Try not to complete the transaction - just fail it.
WriteLOG
Transaction_1123: BEGIN
money=20; endTime=16_07_2016
WriteLOG
Transaction_1123: END
money=10; endTime=16_08_2016
What happens if system crash during writing the log? or during the rollback?
Q5.2: dataset contains bad data
- one user id have 2 corresponding pro-services information.
- Shallow user: a pro-services info does not have corresponding user.
Solution: have a checker class.
Q5.3: simutaneous purchase by 2 users
Solution: lock.
- first process lock money & endTime.
- Read money = 20
- another process try to lock, but end up waiting (sleeping).
- first process do the job, and release the lock.
- another process wakes up.
lock have time-out settings. It can be applied in distributed system as well.
Question: does lock make your execution slow?
If another process is sleeping, CPU will be fully consumed by other process. So it won’t impact.
You can do some async processing, too.
When you lock, try to lock only a small piece of code, not the entire method. In DB, lock only a row, not a table.
Java CAS (Compare and swap )
Q5.4: Server crash
Solution: duplication.
How many copies?
Google did 3. Normally 2 in same data center, and 1 in another location.
Backup data normally is on another machine. But there’s also RAID (redundant array of independent disks) which:
combines multiple physical disk drive components into a single logical unit for the purposes of data redundancy, performance improvement, or both.
When does the copy happen?
Option 1 is doing everyday nightly. This is called a ‘check point’.
Option 2 is use another server to support Shadow Redundancy. All data from Machine 0 will be copied to Machine 1 WHILE it happens. The result is, Machine 1 is identical to Machine 0. If Machine 0 crashes, Machine 1 may be behind less than 1 second.
The way to duplicate is either re-play all the actions, or to read Machine 0’s log and apply the new data.
How to copy?
User send data to 1 server, and from that server, pipeline. This ensures good usage of server bandwith, and serial transfer of data ensures low latency (several ms).
It’s also possible to do tree-like transfer, but the above method is preferred cuz all machine consume same bandwidth.
What is log?
It is actually ‘checkpoint’ + log. It allows you to rollback.
Data redundancy - Summary:

Final note: Data inconsistency
Main sources of inconsistency comes from:
- network fault
- disk error
The disk eror is solved by checksum (compare during disk writing).
Summary
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably.
Atomicity: all or nothing
Q5.1: System crash when purchasing VIP
Consistency: validate according to defined rules
Q5.2: dataset contains bad data
Isolation: independency between transactions (lock)
Q5.3: simutaneous purchase by 2 users
Durability: stored permanently
Q5.4: Server crash
Additional Questions:
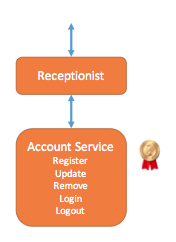
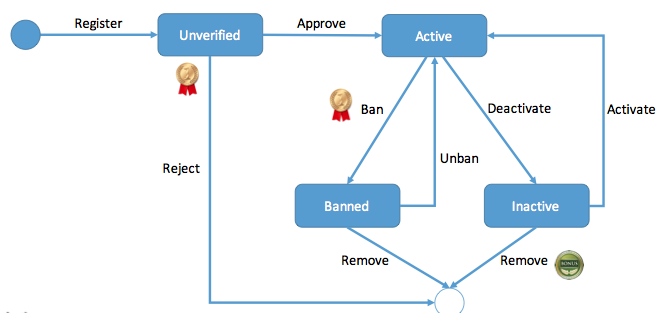
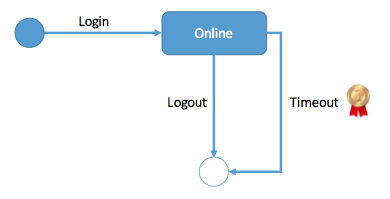
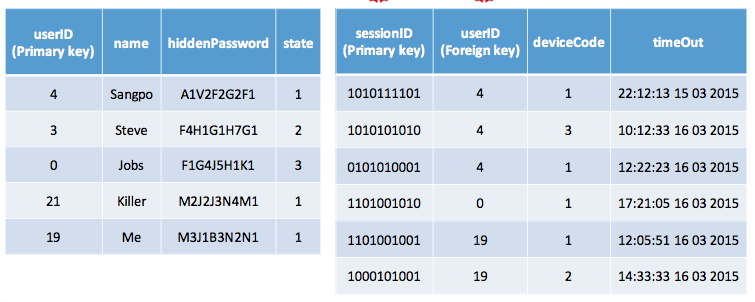
- design a user system (Netflix 2015)
Hint: table design, register, login/out, password check, find password.
- Design payment system (Yelp, BigCommerce 2015)
Hint: the question does not ask about table/ds design itself, but rather the problems associated with payment. Read about ACID principle.